Frequent Online AttacksAn increasing trend in personal attacks on Twitter has created an environment on social media where others are targeted for their race, sexual orientation, disabilities, and much more.
|
Users Disciplined on Twitter for Content
July 2020-December 2020 Million Tweets Removed
July 2020-December 2020 |
Behind the Scenes
The data is composed of about 24,000 tweets derived from the Kaggle Hate Speech and Offensive Language Dataset.
The original dataset was conceived to be used to research hate speech such as racial, homophobic, sexist, and general offensive language. It had the following columns that we later modify: hate_speech, offensive_language, and neither.
Since we wanted to help users reflect deeper about the type of offensive language they may be putting out into the world, we decided to alter the dataset in the following ways:
Example Tweets:
The original dataset was conceived to be used to research hate speech such as racial, homophobic, sexist, and general offensive language. It had the following columns that we later modify: hate_speech, offensive_language, and neither.
Since we wanted to help users reflect deeper about the type of offensive language they may be putting out into the world, we decided to alter the dataset in the following ways:
- We began by creating the following columns: 'Neutral', 'General Criticism', 'Disability Shaming', 'Sexism', 'Racial Prejudice', and 'LGBTQ+ Phobic'.
- Since these new labels were not present in the original dataset, we needed to relabel using our new columns.
- Language is fundamentally complex and context is important to discern more subtle offensive sentences and phrases. We wanted to be mindful, accurate, and consistent with our relabeling process. To do this we created a labeling methodology [link here] that each one of our members followed while manually reading and relabeling thousands of tweets.
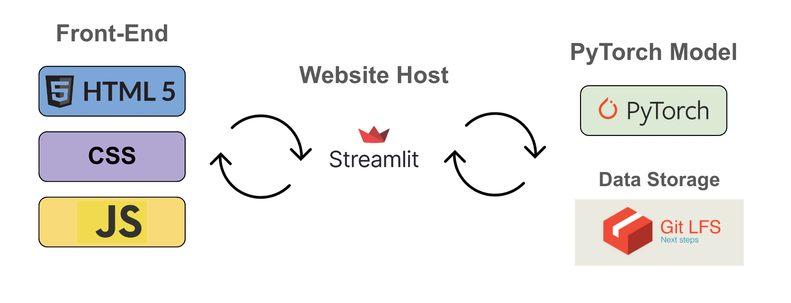
- We then fed our newly relabeled into our PyTorch model where we train the machine learning algorithm to recognize hate speech and predict the type of offensive language.
Example Tweets:

|

|
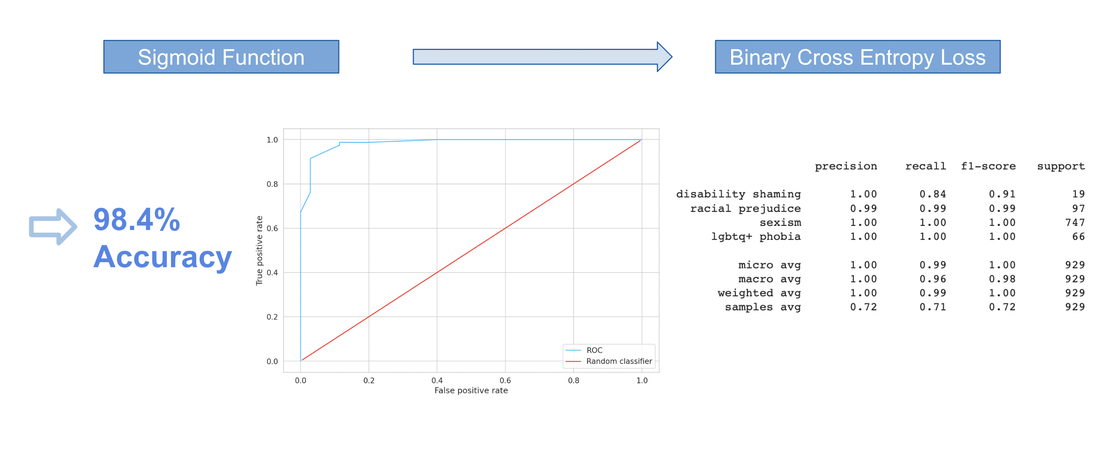
When training our BERT model, we train for 4 epochs using a batch size of 32 , an initial learning rate of 2e-5, and specifying a maximum token length of 50. To specify the maximum amount of token embeddings we want our BERT model to assess when encoding a tweet, we analyze the distribution of token lengths for all of our tweets. Our model uses a pre-trained cased-BERT model and a linear layer to convert the BERT representation to a classification task. We feed our embedded inputs into a sigmoid activation function and use a binary cross entropy loss function.
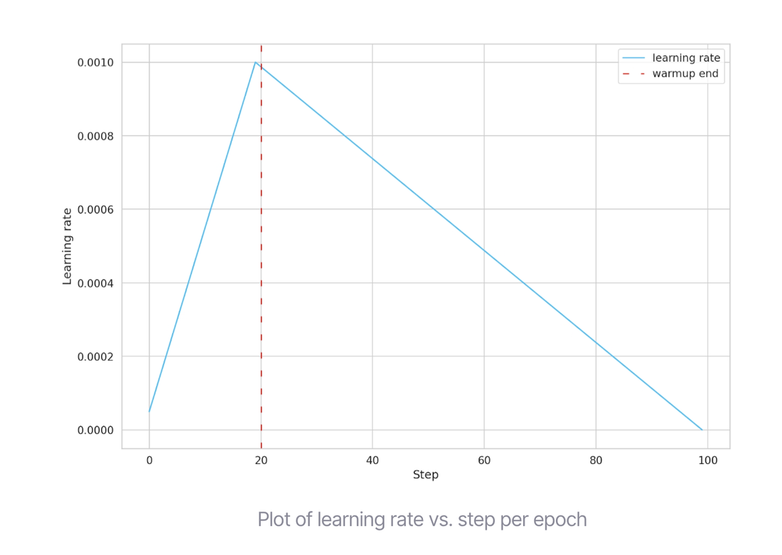
Using the PyTorch Lightning module, we built a standard pipeline that will train almost every model imaginable. We imported two key functionalities: The first is ModelCheckpoint - checkpointing that saves the best model based on minimum validation loss. The second is the learning rate of our model vs each step per epoch. To accomplish this variability, we use an “optimizer scheduler” to change the learning rate of the optimizer during training, which led to better performance of our model. We simulated 100 training steps and told the scheduler to “warm up” for the first 20 steps, starting from our initially specified learning rate of 2e-5, and working up to 0.001, and then linearly working its way down to zero. Our model delivered optimal results using 2 epochs.
Using the PyTorch Lightning module, we built a standard pipeline that will train almost every model imaginable. We imported two key functionalities: The first is ModelCheckpoint - checkpointing that saves the best model based on minimum validation loss. The second is the learning rate of our model vs each step per epoch. To accomplish this variability, we use an “optimizer scheduler” to change the learning rate of the optimizer during training, which led to better performance of our model. We simulated 100 training steps and told the scheduler to “warm up” for the first 20 steps, starting from our initially specified learning rate of 2e-5, and working up to 0.001, and then linearly working its way down to zero. Our model delivered optimal results using 2 epochs.